
Como muitos de vocês, incorporo regularmente as ferramentas de IA para acompanhar as tendências de marketing e Martech. Eles me proporcionam resumos e insights com os quais eu concordo ou discordo.
Enquanto pesquisava tendências de gerenciamento de dados não estruturadas, me deparei com esse resumo do ChatGPT de vários artigos e imediatamente ri alto.
“… o resultado é que As empresas precisarão tratar dados não estruturados com o mesmo cuidado que dados estruturados – Aplicando a governança e as verificações de qualidade – porque está se tornando uma entrada crítica. ”
Minha reação foi: “Oh #@%*! – o mesmo Cuidado?! Estamos com problemas! ”
Se você é um líder da Martech ou MOPS acusado da gestão e qualidade dos dados da sua organização, isso não é necessariamente notícias edificantes.
O impacto e a importância do gerenciamento de dados não estruturados será o meu tema em 2025, porque acredito que a IA generativa fará disso um desafio premente. Há muito o que descompactar neste único tópico. Literalmente, não podemos tratá -lo com o “mesmo cuidado”, pois isso arriscaria problemas de produtividade e qualidade e impactos ainda maiores na marca.
O que queremos dizer com dados não estruturados?
Os dados não estruturados podem incluir postagens de mídia social, cópia corporal de email, análises de clientes ou qualquer forma de conteúdo. Pode ser uma forma curta ou longa. Só precisa ser informações que tradicionalmente não foram forçadas a um formato padronizado.
Além de definir a categoria de conteúdo e/ou o tipo de mídia e os metadados de rastreamento simples, os dados não estruturados não possuem um formato padronizado que podemos facilmente limitar a queda de queda em CRMs e plataformas de automação de marketing (MAPS).
Isso não significa que não tentamos. Uma pesquisa clássica de clientes, por exemplo, pode ter uma escala de classificação estruturada, juntamente com suas respostas não estruturadas de texto livre.
Como os dados não estruturados não se encaixam perfeitamente, sua utilidade diária é frequentemente minimizada em relação a outros dados de marketing-mesmo sabendo que eles contêm informações ricas sobre o sentimento do cliente, tendências ou insights de uso de produtos ou serviços.
Cavar mais: 3 maneiras de aumentar o valor do seu programa de COV através do gerenciamento de jornada
Dados estruturados e não estruturados criam desafios semelhantes
Deixe de lado o surgimento de IA generativa no momento. Os desafios fundamentais do gerenciamento de dados que abrangem dados estruturados e não estruturados são muito semelhantes.
Eles incluem:
- Governança: Ambos os tipos de dados falta de processos e definições acordados.
- O que é “bom o suficiente?” Todos nós fazemos trocas diariamente para explicar as questões de hoje e as campanhas ainda são lançadas. Prazos reais e ou artificiais que nos forçam a reconhecer um padrão mínimo sempre existirá.
- Pressão para fazê -lo! Novos membros da equipe e iniciativas em ritmo acelerado que dificultam a sensação de que estamos fazendo progressos suficientes antes que a próxima onda de limpeza comece inevitavelmente.
Esses desafios fundamentais serão testados ainda mais graças ao influxo de dados e conteúdo recém-gerados e novas plataformas e recursos infundidos com IA, que reivindicarão mais benefícios do tipo unicórnio para as organizações.
Qual é o tamanho do problema de dados não estruturados?
Um estudo frequentemente citado pela IDC e Box conduzido em 2022 encontrou 90% dos dados gerados pelas organizações não são estruturados. As descobertas foram apresentadas em um white paper publicado em 2023. Observe que esse tempo estava em paralelo com a IA generativa começando a atingir o mainstream.
Portanto, podemos esperar que a porcentagem proporcional de dados não estruturados esteja subindo ainda mais rápida quando jogamos conteúdo gerado pela IA no mix, bem como conteúdo multimodal (imagem, áudio/voz e vídeo).
Isso significa que estamos prestes a ser atingidos com uma onda de problemas de gerenciamento de dados que desafiarão qualquer pilha da Martech.
Você mais profundo: A IA está pronta para atrapalhar o mundo dos vendedores e usuários da Martech
O desafio de dados não estruturado está sendo reconhecido?
Em 2024, o Salesforce e o HubSpot anunciaram aquisições de plataformas especificamente direcionadas a problemas de dados não estruturados. Fique de olho em como isso é lançado em novos recursos e/ou recursos incorporados no final de 2025.
Não é de surpreender que o relatório da Martech para 2025 da Scott Brinker e Martech Tribe sinalizou isso como uma área para assistir a 2025, à medida que a equipe provocou essas tendências ainda mais.
“A capacidade de lidar com dados não estruturados na nuvem é crucial para desbloquear o valor da IA generativa”
“A IA generativa está mudando isso, fornecendo a capacidade de absorver e sintetizar grandes quantidades de conteúdo não estruturado em novos casos de uso criativo”.
Títulos e personas: um exemplo simples, mas impactante
Você provavelmente já trabalhou ou agora está trabalhando, um conjunto acordado de personas para desenvolver conteúdo direcionado e focado no cliente. Na maioria dos sistemas de CRM/mapa, isso resulta em um conjunto de menus suspensos padrão que são co-gerenciados pelas operações de vendas e marketing.
Em muitas organizações, isso envolve uma combinação de hierarquia (C-suite, gerente, etc.) ou personas baseadas em funções. Mas, na realidade, todos sabemos que uma persona totalmente desenvolvida não está apenas usando o cargo de alguém. Todos nós começamos por aí. Os títulos de emprego das pessoas são realmente completamente não estruturados e estão sujeitos a suas próprias preferências no LinkedIn ou aos padrões de seus negócios.
Para conciliar isso, estruturamos fluxos de trabalho como este: “contém _keywords__”, no qual agrupamos perfis em “personas predefinidas”. Embora sejam consideradas simples, essas opções influenciam uma série inteira de processos únicos ou de campanha e conteúdo em andamento. Eles são a base para o seu conteúdo que está sendo entregue às pessoas certas na web, email e canais sociais.
Tomemos, por exemplo, alguém com “contrato” em seu cargo. Dependendo do contexto adicional, isso pode significar uma série inteira de papéis e responsabilidades diferentes, desde a conformidade e conformidade, fornecimento/compras, em tempo integral versus consultor. São claramente três personas diferentes com impactos variados em um processo de compra.
Considere este cenário: um contato é marcado inicialmente em uma persona legal/de conformidade devido à palavra -chave “contrato” em seu título, mas eles nunca se envolvem com o conteúdo direcionado a essa persona. Uma análise adicional dos dados não estruturados pode fornecer alertas de que talvez a persona baseada em título estivesse incorreta.
Também poderíamos analisar outros dados não estruturados, a partir de seu perfil público ou dados capturados internamente, como email, por exemplo. Se o contato foi posteriormente entre as reuniões em que transcrições ou gravações estiverem disponíveis ou, se os e -mails com sua equipe começaram a fazer referência a um processo de RFP, o sentimento e os dados não estruturados poderão desencadear um fluxo de trabalho que requer sua categorização e potencialmente os transmitir a uma persona de fornecimento/compras. Isso seria extremamente impactante em qualquer qualificação de conta ou processo de gerenciamento de negócios.
Oportunidades e desafios aguardam
Um exemplo esperançoso dessa capacidade incorporada no MAP/CRM foi destacado em um dos meus artigos no ano passado. Espero que os recursos de IA permitam rastrear o “tom” de um cliente para gerar melhor personalização, com base em interações anteriores, em vez de suspensos ou modelos predefinidos que ainda são amplamente definidos.
Precisamos de plataformas de mapa/CRM para nos ajudar a navegar nesses desafios, sendo ainda mais transparentes com o uso da IA incorporada.
Por exemplo: o que realmente está acontecendo quando você verifica a caixa “Dados de conversas do cliente” nos novos recursos de IA do Hubspot.
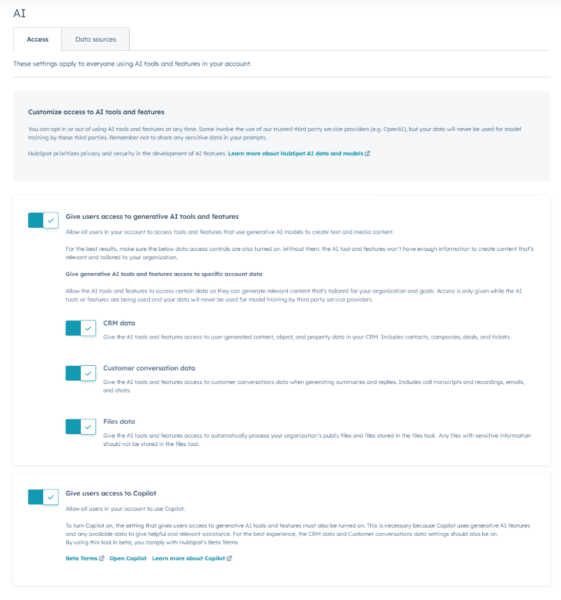
Se esses recursos forem ativados por padrão, todos parecem ajudar a gerar ainda mais conteúdo. Espero que eles também possam ser ajustados para primeiro nos ajudar a analisar e entender os dados, em vez de apenas assumir que isso acontece corretamente nos bastidores.
Por onde começar
Você pode se preparar para os desafios dos dados não estruturados, revisitando seus processos fundamentais para explicar seu impacto.
Procedimentos de governança
Expanda seus processos e políticas para incluir dados recém -estruturados – de origem externa e gerenciados internamente.
Especificamente, recomendo que comecemos a considerar um novo tipo de metadados para reconhecer o tipo de dados original (não estruturado) e rastrear se for posteriormente transformado em dados estruturados. Temos que rastrear a “cadeia de custódia de dados” semelhante a uma fonte de chumbo em atribuição.
As novas plataformas Martech infundidas com IA processarão esses dados com os modelos de processamento de linguagem natural e LLM, com a promessa de estruturá-los para você. Se não capturarmos o contexto original, será perdido para sempre, uma vez que a IA generativa é um mecanismo de previsão e não é determinístico.
Comece a determinar o que é ‘bom o suficiente’
Precisamos estabelecer novos KPIs que nos permitam avaliar/avaliar a qualidade e o impacto dos dados não estruturados. Não podemos mais confiar em medidas simples, como taxas de conclusão ou identificadores exclusivos.
Precisamos desenvolver novos métodos de amostragem de dados para avaliar como os processos de estruturação infundidos com IA estão funcionando. Lembre-se de que os modelos de IA não são baseados em regras, como nosso CRM/mapa.
Faça isso
Teremos que fazer trocas dentro de nossos roteiros originais, focados em combater principalmente dados estruturados. Precisamos realocar esses recursos e investimentos para começar a enfrentar desafios de dados não estruturados. Isso incluirá novos esforços multifuncionais para trabalhar com equipes de atendimento ao cliente e produtos que possuem plataformas fora da pilha Martech para críticas, dados de sentimentos, pesquisa etc.
Notavelmente, também devemos começar com um investimento no treinamento de alfabetização de IA para equipes de marketing e gerenciamento de dados. Entender por que uma alucinação de IA acontece será fundamental para esta próxima onda de qualidade de dados.
Se não investirmos nesses esforços, o impacto de dados não estruturados será composto em um ritmo exponencial, pois já está se misturando com nossos desafios de qualidade de dados existentes. E o impacto disso não será o mesmo problema que tivemos antes.
Os autores contribuintes são convidados a criar conteúdo para a Martech e são escolhidos por sua experiência e contribuição para a comunidade Martech. Nossos colaboradores trabalham sob a supervisão da equipe editorial e as contribuições são verificadas quanto à qualidade e relevância para nossos leitores. As opiniões que eles expressam são suas.
Fonte ==> Istoé







