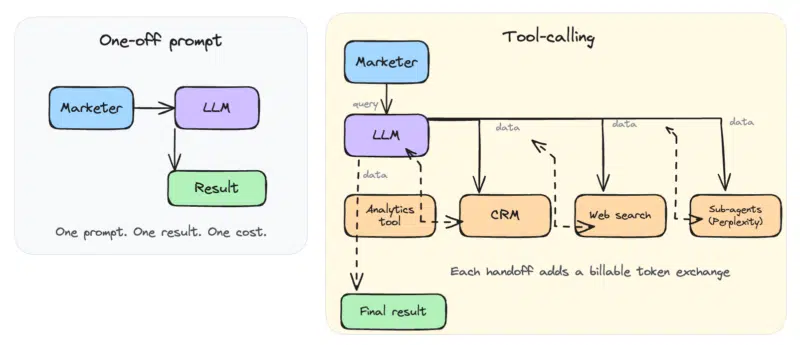
No momento em que a IA se conecta aos sistemas do seu negócio, o chatbot se torna muito mais poderoso. Em vez de responder uma pergunta por vez, ele pode extrair registros de clientes do seu CRM, analisar o desempenho da campanha, pesquisar na web e gerar um relatório personalizado em um único fluxo de trabalho. Isso é possível graças à chamada de ferramenta, que permite que a IA acesse sistemas externos por meio de APIs e conexões Model Context Protocol (MCP).
O resultado é um enorme aumento de produtividade para os profissionais de marketing. A IA pode encadear várias ferramentas sem exigir que os usuários alternem entre os aplicativos. O problema é que cada chamada de ferramenta consome tokens. Os agentes de IA, em particular, usam um número incrível deles porque passam todo o histórico de tarefas, seu raciocínio interno e quaisquer dados de ferramentas externas de volta ao modelo em cada etapa do ciclo de resolução de problemas.
A realidade do limite de token
Vejamos um exemplo real de como isso funciona.
Um pipeline diário típico – pesquisar 200 resultados, resumi-los, gerar cinco variações de título – pode facilmente executar de 4.000 a 5.000 tokens ou mais por execução. Ao longo de um mês de 30 dias, isso pode atingir bem mais de 100.000 tokens, muito além dos limites de nível gratuito em plataformas OpenAI, Anthropic e similares, e até mesmo o suficiente para gastar uma assinatura de US$ 20 bem antes do final do mês.
(Todas as estimativas de token neste artigo são baseadas em métricas de tokenização padrão usadas em todo o setor – o mesmo método que os provedores usam para calcular sua fatura. São projeções aproximadas, não medidas exatas de um pipeline ao vivo, e o uso real varia de acordo com o modelo, estrutura de prompt e comprimento de saída.)
Por que Claude Cowork e fluxos de trabalho semelhantes atingiram o muro
Claude Cowork e outros ambientes com muitas ferramentas tornam o problema visível rapidamente. Cada arquivo lido, cada pesquisa, cada chamada de API adiciona uma interação de token faturável. Os usuários que começam o mês com uma assinatura de US$ 20 geralmente ficam limitados na segunda semana.
A consequência é escolher entre limitar seu fluxo de trabalho ou pagar taxas excedentes surpreendentes. Nenhum dos dois é sustentável para uma equipe de marketing que precisa executar pipelines diariamente.
A resposta é o contexto de propriedade, não um único provedor
Felizmente, existe uma solução: mantenha os dados brutos sob seu controle. Armazene-o em um banco de dados de equipe compartilhado como PostgreSQL ou Qdrant, em um data warehouse em nuvem como Snowflake ou BigQuery, ou em uma pasta em armazenamento em nuvem compartilhado — e use uma lógica de filtragem leve e não LLM para extrair peças relevantes antes que qualquer coisa toque o modelo.
Configurar isso pode envolver um LLM uma vez, da mesma forma que você usaria um assistente de IA para escrever uma fórmula ou script. Mas, uma vez implementado, ele é executado automaticamente em cada lote de novos dados – e não chama nenhum LLM. Pontuação simples de palavras-chave ou pesquisa de similaridade vetorial, ambas ordens de magnitude mais baratas do que uma chamada LLM, classificam os dados por relevância.
Quando um pipeline de escuta social extrai 500 tweets sobre uma marca, a etapa de filtragem seleciona silenciosamente os 10 mais relevantes e envia apenas esses para o modelo. A conta simbólica normalmente cai 60% ou mais. A qualidade do insight permanece a mesma.
Além do agente único
Existem várias ferramentas que podem fazer esse tipo de filtragem. O Hermes Agent de código aberto, Claude Cowork, Claude Code e Perplexity Computer conectam um LLM a ferramentas externas, permitindo chamar APIs, ler arquivos e automatizar fluxos de trabalho que podem exigir a alternância entre meia dúzia de aplicativos. No entanto, o Hermes é executado em sua infraestrutura e é independente de provedor. Os demais estão atrelados aos modelos e infraestrutura da Antrópica e da Perplexidade.
Outras ferramentas notáveis no ecossistema mais amplo de agentes incluem:
- OpenClaw (mais de 380 mil estrelas no GitHub), um agente de código aberto que combina com armazenamentos de memória baseados em sistema de arquivos;
- OpenAI Codex CLI (93 mil estrelas), que dá aos desenvolvedores acesso de agente baseado em terminal com persistência de arquivo local; e
- Estruturas de orquestração como LangChain (140 mil estrelas) e CrewAI (54 mil estrelas), nas quais você constrói em vez de usar diretamente.
O que todos eles compartilham, de maneiras diferentes, é que o modelo é um convidado no seu sistema, não o proprietário.
Hermes leva esse princípio ao extremo. Ele mantém um armazenamento de contexto local persistente – seu histórico de conversas, saídas de ferramentas e incorporações estão em seu banco de dados e acessíveis entre sessões. Além disso, uma camada de memória aprende com cada interação, capturando preferências, correções e padrões recorrentes para que o agente melhore com o tempo, em vez de iniciar cada sessão do zero.
Seus clientes pesquisam em qualquer lugar. Certifique-se de que sua marca aparece.
O kit de ferramentas de SEO que você conhece, além dos dados de visibilidade de IA de que você precisa.
Comece o teste gratuito
Comece com

Seu ecossistema de ferramentas integrado (web, terminal, APIs, visão, Python) significa o mesmo pipeline que extrai registros do Salesforce ou HubSpot, verifica um data warehouse e elabora um relatório, também captura os resultados intermediários e os salva localmente. E, por ser independente de provedor, você só precisa alterar uma linha de configuração para passar do OpenRouter para um LLaMA auto-hospedado.
O produto é a implementação. O padrão é o que importa – e qualquer equipe pode adotá-lo. A mensagem não é “use Agente Hermes”. A mensagem é “comece a construir sistemas que permitam que você seja o dono do seu contexto, porque a abordagem centrada no provedor não pode ser escalonada”.
O impulso por trás das ferramentas agênticas e de propriedade do contexto é inconfundível. Mas a verdadeira questão que estas ferramentas impõem é estratégica: quer pagar pelo trabalho, ou possuir a infra-estrutura e pagar pelo raciocínio? Mude para uma assinatura maior e provavelmente você ainda ficará sem capacidade. Uma arquitetura diferente elimina totalmente esse problema. A escolha que toda equipe de marketing enfrenta é em que lado da equação ela deseja estar.
Esta é a primeira de uma série de três partes sobre a mudança em direção a fluxos de trabalho de marketing de agentes e a infraestrutura necessária para apoiá-los. Na Parte 2, examino como a arquitetura funciona na prática. A Parte 3 aborda os primeiros passos com o Hermes Desktop – a instalação, habilidades e fluxos de trabalho reais.
Fonte ==> Istoé







