Quer insights mais inteligentes em sua caixa de entrada? Inscreva -se para que nossos boletins semanais obtenham apenas o que importa para a IA, dados e líderes de segurança corporativos. Inscreva -se agora
Liquid AI lançou LFM2-VLuma nova geração de modelos de fundação em linguagem de visão Projetado para implantação eficiente em uma ampla gama de hardware – De smartphones e laptops a wearables e sistemas incorporados.
Os modelos prometem desempenho de baixa latência, forte precisão e flexibilidade para aplicativos do mundo real.
O LFM2-VL se baseia na arquitetura LFM2 existente da empresa, estendendo-a ao processamento multimodal que suporta entradas de texto e imagem em resoluções variáveis.
De acordo com a AI líquida, o Os modelos oferecem até o dobro da velocidade de inferência da GPU de modelos comparáveis de linguagem de visãomantendo o desempenho competitivo em benchmarks comuns.
Ai escala atinge seus limites
Capitões de energia, custos crescentes de token e atrasos de inferência estão remodelando a IA corporativa. Junte -se ao nosso salão exclusivo para descobrir como são as principais equipes:
- Transformando energia em uma vantagem estratégica
- Arquitetagem Inferência eficiente para ganhos reais de rendimento
- Desbloqueando o ROI competitivo com sistemas de IA sustentáveis
Prenda seu lugar para ficar à frente: https://bit.ly/4mwgngo
“A eficiência é o nosso produto”, escreveu o co-fundador e CEO da Liquid IA Ramin Hasani Em um post sobre X anunciando a nova família modelo:
Duas variantes para diferentes necessidades
O lançamento inclui dois tamanhos de modelo:
- LFM2-VL-450M -Um modelo hiper-eficiente com menos de meio bilhão de parâmetros (configurações internas) destinado a ambientes altamente restritos a recursos.
- LFM2-VL-1.6B -Um modelo mais capaz que permanece leve o suficiente para implantação baseada em GPU e dispositivo único.
Ambas as variantes processam imagens em resoluções nativas de até 512 × 512 pixels, evitando distorção ou aumento desnecessário.
Para imagens maiores, o sistema aplica patches sem sobreposição e adiciona uma miniatura para o contexto global, permitindo que o modelo capture detalhes finos e cena mais ampla.
Antecedentes na AI líquida
A IA Liquid foi fundada por ex -pesquisadores do Laboratório de Ciência da Computação e Ciência da Computação do MIT (CSAIL) com o objetivo de construir arquiteturas de IA que vão além do modelo de transformador amplamente utilizado.
A principal inovação da empresa, os Modelos da Fundação Liquid (LFMS), baseia-se em princípios de sistemas dinâmicos, processamento de sinais e álgebra linear numérica, produzindo modelos de IA de uso geral capazes de lidar com texto, vídeo, áudio, séries temporais e outros dados seqüenciais.
Ao contrário das arquiteturas tradicionais, a abordagem do Liquid visa oferecer desempenho competitivo ou superior usando significativamente menos recursos computacionaispermitindo adaptabilidade em tempo real durante a inferência, mantendo os baixos requisitos de memória. Isso faz com que o LFMS seja adequado para casos de uso corporativo em larga escala e implantações de borda limitadas por recursos.
Em julho de 2025, a empresa expandiu sua estratégia de plataforma com o lançamento da plataforma Liquid Edge AI (LEAP), Um SDK de plataforma cruzada projetada para facilitar a execução de modelos de idiomas pequenos diretamente em dispositivos móveis e incorporados.
O LEAP oferece suporte AS-Agnóstico para iOS e Android, integração com os próprios modelos do Liquid e outros SLMs de código aberto e uma biblioteca embutida com modelos tão pequenos quanto 300 MB-pequeno o suficiente para os telefones modernos com RAM mínima.
Seu aplicativo complementar, Apollo, permite que os desenvolvedores testem modelos totalmente offline, alinhando-se com a ênfase da IA líquida na IA de baixa preservação de privacidade e IA de baixa latência. Juntos, Leap e Apollo refletem o compromisso da empresa em descentralizar a execução da IA, reduzir a dependência da infraestrutura em nuvem e capacitar os desenvolvedores a criar modelos otimizados e específicos de tarefas para ambientes do mundo real.
Speed/Quality Trade-offs e design técnico
LFM2-VL usa uma arquitetura modular Combinando um backbone do modelo de idioma, um codificador Siglip2 Naflex Vision e um projetor multimodal.
O projetor inclui um conector MLP de duas camadas com o pixel desnutal, reduzindo o número de tokens de imagem e melhorando a taxa de transferência.
Os usuários podem ajustar parâmetros como o número máximo de tokens ou patches de imagem, permitindo que eles equilibrem velocidade e qualidade, dependendo do cenário de implantação. O processo de treinamento envolveu aproximadamente 100 bilhões de tokens multimodais, provenientes de conjuntos de dados abertos e dados sintéticos internos.
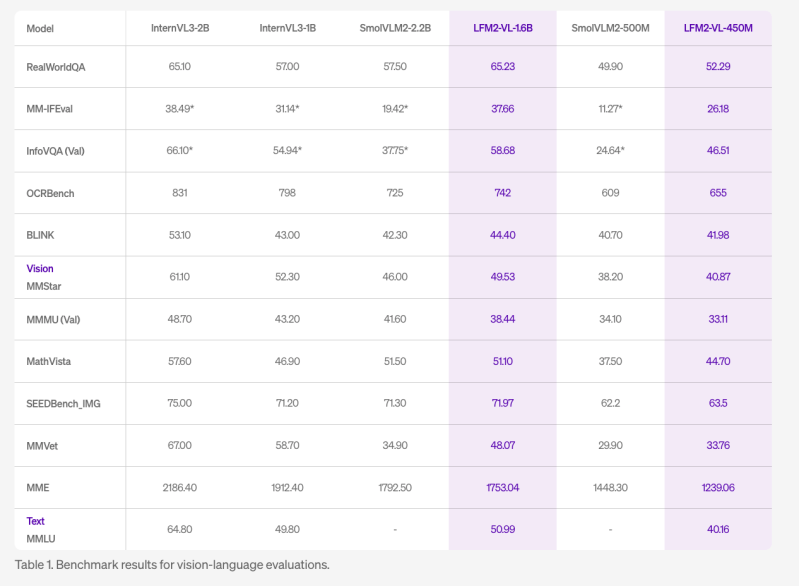
Desempenho e benchmarks
Os modelos alcançam resultados competitivos de referência em uma série de avaliações de linguagem da visão. LFM2-VL-1.6B pontuam bem em realworldqa (65,23), Infovqa (58,68) e Ocrbench (742) e mantém resultados sólidos em tarefas de raciocínio multimodal.
No teste de inferência, o LFM2-VL alcançou os tempos de processamento da GPU mais rápidos em sua classe quando testados em uma carga de trabalho padrão de uma imagem de 1024 × 1024 e um prompt curto.

Licenciamento e disponibilidade
Os modelos LFM2-VL já estão disponíveis no Hugging Face, juntamente com o exemplo de código de ajuste fino no COLAB. Eles são compatíveis com transformadores de rosto abraçados e TRL.
Os modelos são lançados sob uma “licença LFM1.0 personalizada”. A IA Liquid descreveu essa licença com base nos princípios do Apache 2.0, mas o texto completo ainda não foi publicado.
A empresa indicou que o uso comercial será permitido sob determinadas condições, com diferentes termos para empresas acima e abaixo de US $ 10 milhões em receita anual.
Com o LFM2-VL, a Liquid AI pretende tornar a IA multimodal de alto desempenho mais acessível para implantações no dispositivo e com recursos limitados, sem sacrificar a capacidade.

Fonte ==> Cyberseo