Quer insights mais inteligentes em sua caixa de entrada? Inscreva -se para que nossos boletins semanais obtenham apenas o que importa para a IA, dados e líderes de segurança corporativos. Inscreva -se agora
Um novo estudo abrangente revelou que os modelos de inteligência artificial de código aberto consomem significativamente mais recursos de computação do que seus concorrentes de código fechado ao executar tarefas idênticas, potencialmente prejudicando suas vantagens de custo e reformulando como as empresas avaliam as estratégias de implantação da IA.
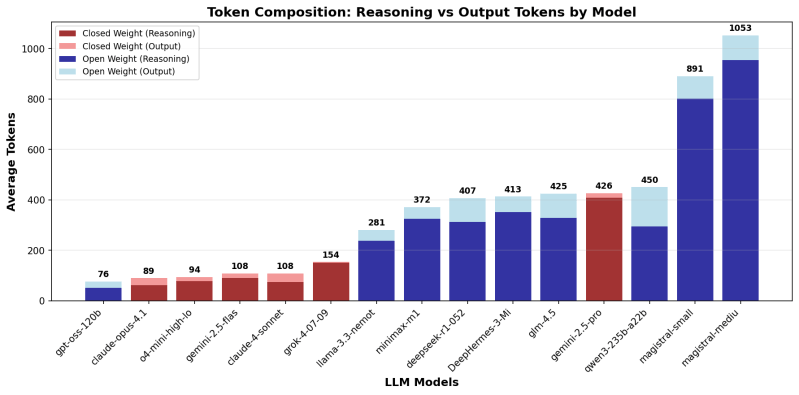
A pesquisa, conduzida pela empresa de IA Nous Research, descobriu que os modelos de peso aberto usam entre 1,5 a 4 vezes mais tokens-as unidades básicas da computação de IA-do que modelos fechados como os do OpenAI e Antrópico. Para perguntas simples de conhecimento, a lacuna aumentou drasticamente, com alguns modelos abertos usando até 10 vezes mais tokens.
Medindo a eficiência do pensamento nos modelos de raciocínio: os benchmarkhttps ausentes: //t.co/b1e1rjx6vz
Medimos o uso do token entre os modelos de raciocínio: modelos abertos emitir 1,5-4x a mais tokens do que modelos fechados em tarefas idênticas, mas com enorme variação, dependendo do tipo de tarefa (até… pic.twitter.com/ly1083won8
– Nous Research (@NousRearch) 14 de agosto de 2025
“Os modelos de peso aberto usam 1,5 a 4 × mais tokens do que os fechados (até 10 × para perguntas simples de conhecimento), tornando -as às vezes mais caras por consulta, apesar dos custos mais baixos por toque”, escreveram os pesquisadores em seu relatório publicado na quarta -feira.
Os resultados desafiam uma suposição predominante na indústria de IA de que os modelos de código aberto oferecem vantagens econômicas claras sobre alternativas proprietárias. Embora os modelos de código aberto normalmente custem menos por token para executar, o estudo sugere que essa vantagem pode ser “facilmente compensada se exigir mais tokens para raciocinar sobre um determinado problema”.
Ai escala atinge seus limites
Capitões de energia, custos crescentes de token e atrasos de inferência estão remodelando a IA corporativa. Junte -se ao nosso salão exclusivo para descobrir como são as principais equipes:
- Transformando energia em uma vantagem estratégica
- Arquitetagem Inferência eficiente para ganhos reais de rendimento
- Desbloqueando o ROI competitivo com sistemas de IA sustentáveis
Prenda seu lugar para ficar à frente: https://bit.ly/4mwgngo
O custo real da IA: por que os modelos ‘mais baratos’ podem quebrar seu orçamento
A pesquisa examinou 19 modelos diferentes de IA em três categorias de tarefas: questões básicas de conhecimento, problemas matemáticos e quebra -cabeças lógicos. A equipe mediu a “eficiência do token” – quantas unidades computacionais os modelos usam em relação à complexidade de suas soluções – uma métrica que recebeu pouco estudo sistemático, apesar de suas implicações significativas de custo.
“A eficiência do token é uma métrica crítica por várias razões práticas”, observaram os pesquisadores. “Embora a hospedagem de modelos de peso aberto possa ser mais barato, essa vantagem de custo pode ser facilmente compensada se exigir mais tokens para raciocinar sobre um determinado problema”.
A ineficiência é particularmente pronunciada para grandes modelos de raciocínio (LRMS), que usam “cadeias de pensamento” estendidas para resolver problemas complexos. Esses modelos, projetados para pensar em problemas passo a passo, podem consumir milhares de tokens ponderando perguntas simples que devem exigir computação mínima.
Para perguntas básicas de conhecimento como “Qual é a capital da Austrália?” O estudo descobriu que os modelos de raciocínio gastam “centenas de tokens ponderando perguntas simples de conhecimento” que podem ser respondidas em uma única palavra.
Que os modelos de IA realmente entregam bang para o seu dinheiro
A pesquisa revelou fortes diferenças entre os provedores de modelos. Os modelos da OpenAI, particularmente seus O4-Mini e as variantes GPT-OSS de código aberto recém-lançadas, demonstraram eficiência excepcional de token, especialmente para problemas matemáticos. O estudo descobriu que os modelos OpenAI “se destacam para a eficiência de token extrema em problemas de matemática”, usando até três vezes menos fichas do que outros modelos comerciais.
Entre as opções de código aberto, a llama-3.3-Nemotron-Super-49B-V1 da NVIDIA emergiu como “o modelo de peso aberto mais eficiente de token em todos os domínios”, enquanto modelos mais novos de empresas como o magistral mostraram “uso excepcionalmente alto de token” como outliers.
A lacuna de eficiência variou significativamente pelo tipo de tarefa. Embora os modelos abertos usassem aproximadamente o dobro de tokens para problemas matemáticos e lógicos, a diferença aumentou para perguntas simples de conhecimento, onde o raciocínio eficiente deve ser desnecessário.

O que os líderes corporativos precisam saber sobre os custos de computação de IA
Os resultados têm implicações imediatas para a adoção da IA corporativa, onde os custos de computação podem escalar rapidamente com o uso. As empresas que avaliam os modelos de IA geralmente se concentram nos benchmarks de precisão e nos preços por toque, mas podem ignorar os requisitos computacionais totais para tarefas do mundo real.
“A melhor eficiência do token dos modelos de peso fechado geralmente compensa o preço mais alto da API desses modelos”, descobriram os pesquisadores ao analisar os custos totais de inferência.
O estudo também revelou que os provedores de modelos de código fechado parecem estar otimizando ativamente a eficiência. “Os modelos de peso fechado foram otimizados iterativamente para usar menos tokens para reduzir o custo de inferência”, enquanto os modelos de código aberto “aumentaram seu uso de token para versões mais recentes, possivelmente refletindo uma prioridade para um melhor desempenho de raciocínio”.

Como os pesquisadores quebraram o código na medição de eficiência da IA
A equipe de pesquisa enfrentou desafios únicos na medição da eficiência em diferentes arquiteturas de modelos. Muitos modelos de código fechado não revelam seus processos de raciocínio brutos, em vez disso, fornecendo resumos compactados de seus cálculos internos para impedir que os concorrentes copiem suas técnicas.
Para resolver isso, os pesquisadores usaram tokens de conclusão – o total de unidades computacionais cobradas para cada consulta – como proxy para o esforço de raciocínio. Eles descobriram que “os modelos de código fechado mais recentes não compartilharão seus traços de raciocínio cru” e “usarão modelos de linguagem menores para transcrever a cadeia de pensamentos em resumos ou representações compactadas”.
A metodologia do estudo incluiu testes com versões modificadas de problemas conhecidos para minimizar a influência de soluções memorizadas, como alterar variáveis em problemas de competição matemática do Exame de Matemática Americana de Invitational (AIME).

O futuro da eficiência da IA: o que está por vir
Os pesquisadores sugerem que a eficiência do token deve se tornar uma meta de otimização primária, juntamente com a precisão para o desenvolvimento futuro do modelo. “Um berço mais densificado também permitirá o uso de contexto mais eficiente e poderá combater a degradação do contexto durante tarefas desafiadoras de raciocínio”, escreveram eles.
O lançamento dos modelos GPT-ROSS de código aberto da OpenAI, que demonstram eficiência de ponta com “berço acessível”, pode servir como um ponto de referência para otimizar outros modelos de código aberto.
O conjunto de dados de pesquisa completo e o código de avaliação estão disponíveis no GitHub, permitindo que outros pesquisadores validem e estendam as descobertas. À medida que a indústria da IA corre em direção a recursos de raciocínio mais poderosos, este estudo sugere que a concorrência real pode não ser sobre quem pode construir a IA mais inteligente – mas quem pode construir o mais eficiente.
Afinal, em um mundo em que todos os tokens contam, os modelos mais desperdiçados podem se encontrar com preços fora do mercado, independentemente de quão bem eles possam pensar.

Fonte ==> Cyberseo







