Quer insights mais inteligentes em sua caixa de entrada? Inscreva -se para que nossos boletins semanais obtenham apenas o que importa para a IA, dados e líderes de segurança corporativos. Inscreva -se agora
Pesquisadores da KAIST AI e MILA introduziram uma nova arquitetura de transformadores que torna os grandes modelos de idiomas (LLMs) mais eficientes em termos de memória e computação. A arquitetura, chamada Mistura de Recursões (MOR), melhora significativamente a precisão do modelo e oferece maior taxa de transferência em comparação com transformadores de baunilha, mesmo quando restringidos pela mesma contagem de parâmetros e orçamento de computação.
Os desafios de escala do LLMS
As capacidades impressionantes dos LLMs de hoje estão diretamente ligadas ao seu tamanho cada vez maior. Mas, à medida que esses modelos escalam, suas pegadas de memória e requisitos computacionais geralmente se tornam insustentáveis, tornando o treinamento e a implantação desafiadores para organizações fora dos data centers de escala de hiperescala. Isso levou a uma busca por designs mais eficientes.
Os esforços para melhorar a eficiência do LLM se concentraram principalmente em dois métodos: compartilhamento de parâmetros e computação adaptativa. As técnicas de compartilhamento de parâmetros reduzem o número total de parâmetros exclusivos reutilizando pesos em diferentes partes do modelo, reduzindo assim a complexidade computacional geral. Por exemplo, “amarrar camadas” é uma técnica que reutiliza os pesos de um modelo em várias camadas. Os métodos de computação adaptativa ajustam os modelos para que eles usem apenas os recursos de inferência necessários. Por exemplo, a “saída inicial” aloca dinamicamente a computação, permitindo que o modelo pare de processar tokens “mais simples” no início da rede.
No entanto, a criação de uma arquitetura que efetivamente unifica a eficiência dos parâmetros e a computação adaptativa permanece ilusória.
A série de impacto da IA retorna a São Francisco – 5 de agosto
A próxima fase da IA está aqui – você está pronto? Junte-se aos líderes de Block, GSK e SAP para obter uma visão exclusiva de como os agentes autônomos estão remodelando os fluxos de trabalho corporativos-desde a tomada de decisões em tempo real até a automação de ponta a ponta.
Prenda seu lugar agora – o espaço é limitado: https://bit.ly/3guuplf
Como funciona a mistura de recursões
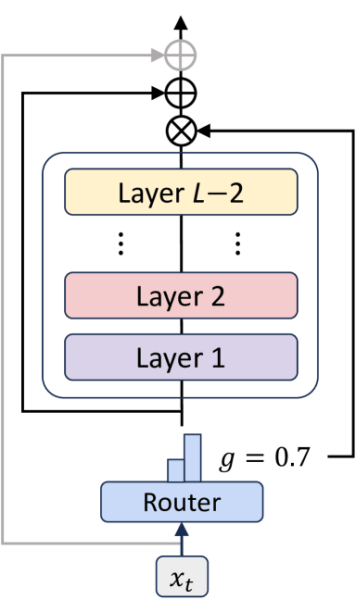
A mistura de recursões é uma estrutura que combina o compartilhamento de parâmetros com a computação adaptativa para atender às altas demandas computacionais do LLMS. Ele se baseia no conceito de transformadores recursivos, modelos que aplicam repetidamente um conjunto de camadas compartilhadas várias vezes. Em vez de uma pilha profunda de camadas exclusivas, um transformador recursivo divide o modelo em alguns “blocos de recursão”, cada um com um pool compartilhado de parâmetros. Esse design permite mais computação sem aumentar o tamanho do modelo.
Mor aprimora essa abordagem recursiva com dois componentes principais. O primeiro é um roteador leve que atribui de maneira inteligente uma profundidade de recursão específica a cada token. Esse conceito é semelhante ao mecanismo de roteamento nos modelos de mistura de especialistas (MOE), onde um roteador direciona tokens para redes especializadas de especialistas. No MOR, no entanto, os “especialistas” são as diferentes profundidades de recursão, permitindo que o modelo escolha quanta computação se aplica a cada token dinamicamente. Ele decide quantas vezes um bloco compartilhado de camadas deve ser aplicado com base na complexidade de um token ou na “profundidade de pensamento” necessária. Isso direciona a computação somente onde é mais necessário, evitando ciclos desperdiçados em partes de fácil processo da entrada.
O segundo componente é uma estratégia de cache de valor-chave mais eficiente (KV). O cache de kv é uma técnica padrão que armazena informações de tokens anteriores para acelerar a geração, mas se torna um gargalo de memória em modelos recursivos. Mor apresenta um mecanismo de cache de KV “recurso” que armazena e recupera seletivamente pares de valor-chave apenas para os tokens que ainda estão ativos em uma determinada etapa de recursão. Esse cache direcionado reduz o tráfego de memória e melhora a taxa de transferência sem a necessidade de modificações complexas pós-treinamento.
Como os pesquisadores afirmam em seu artigo: “Em essência, Mor permite que os modelos ajustem com eficiência sua profundidade de pensamento por token, unificando a eficiência dos parâmetros com a computação adaptativa”.

Mor em ação
Para testar sua estrutura, os pesquisadores treinaram modelos MOR que variam de 135 milhões a 1,7 bilhões de parâmetros e os compararam com a baunilha e os modelos de linha de base recursiva padrão sobre perda de validação e referências de precisão de poucas fotos.
Os resultados demonstram ganhos significativos. Quando recebeu um orçamento de computação de treinamento igual, um modelo MOR alcançou maior precisão média de poucos tiro (43,1% vs. 42,3%) do que uma linha de base de baunilha, apesar de usar quase 50% menos parâmetros. Quando treinado na mesma quantidade de dados, o modelo MOR reduziu o tempo de treinamento em 19% e reduziu o uso de memória de pico em 25% em comparação com o modelo de baunilha.
A arquitetura MOR também prova ser escalável. Embora tenha um desempenho inferior ao modelo de baunilha na menor escala de parâmetros de 135m, a lacuna foi fechada rapidamente à medida que o tamanho do modelo aumentou. Para modelos com mais de 360m de parâmetros, MOR correspondeu ou excedeu o desempenho de transformadores padrão, especialmente em orçamentos de computação mais baixos. Além disso, o design de Mor aumenta drasticamente a taxa de transferência de inferência. Uma configuração MOR alcançou uma aceleração de 2,06x sobre a linha de base da baunilha. Para uma empresa que opera em escala, isso pode se traduzir em uma economia operacional significativa de custos.
Sangmin Bae, co-autor do artigo e um aluno de doutorado em Kaist, interrompeu o impacto prático em um e-mail para VentureBeat. “Embora seja difícil fornecer números exatos, em alto nível, reduzir o tamanho do parâmetro do modelo e a pegada de cache de kv significa que podemos realizar inferência em muitas outras amostras simultaneamente”, disse ele. “Isso se traduz em um número aumentado de tokens processado de uma só vez, e o manuseio de janelas de contexto mais longo se torna viável”.
Um caminho prático para a adoção da empresa
Enquanto os resultados do artigo vêm de modelos treinados do zero, uma questão -chave para as empresas é como adotar o MOR sem investimentos iniciais maciços. Segundo a BAE, os modelos de “aumento” de código aberto é uma “abordagem definitivamente mais econômica”. Ele observou que, ao treinar um novo modelo, é direto, uma “abordagem de subida pode ser mais adequada e eficiente até que a escalabilidade de Mor seja totalmente validada”.
A adoção do MOR também introduz novos “botões” arquitetônicos para os desenvolvedores, permitindo que eles ajustem o equilíbrio entre desempenho e eficiência. Esse trade-off dependerá inteiramente das necessidades do aplicativo.
“Para tarefas ou cenários mais simples, pode ser benéfico usar modelos com mais etapas de recursão, oferecendo maior flexibilidade e vice -versa”, explicou Bae. Ele enfatizou que as “configurações ideais dependerão muito da configuração de implantação específica”, incentivando as equipes a explorar as compensações com base nas descobertas do artigo.
Olhando para o futuro, a estrutura MOR é “modalidade-agnóstico”, o que significa que seus princípios de computação adaptativa não se limitam ao texto. Isso abre a porta para ganhos significativos de eficiência no processamento de vídeos, áudio e outros tipos de dados complexos.
“Estamos muito empolgados com sua extensão potencial a cenários de multimodalidade, onde os ganhos de eficiência são cruciais”, disse Bae.
Ao ajustar dinamicamente a profundidade do processamento para cada segmento de um fluxo de vídeo ou áudio, o MOR poderia desbloquear uma economia de custos ainda maiores e melhorias de desempenho, trazendo o poder da IA em larga escala a uma ampla gama de aplicativos corporativos. Como o artigo conclui, Mor oferece “um caminho eficaz para alcançar recursos de grande modelo com uma sobrecarga computacional e de memória reduzida significativamente”.

Fonte ==> Cyberseo







